
Introduction
When tackling broad and challenging exams like the AWS Solution Architect Professional, you have to ingest a wide breadth and depth of knowledge. You could even venture to say you want to be a jack of all trades and master of all! Not exactly, but it can feel that way. That’s why it’s critical to have a number of years of AWS experience under your belt, solid training courses, and in my opinion, lots of hands-on experience. If there are gaps in your knowledge, the best and fastest way to learn is to supplement your training with hands-on experience.
In this blog series, I want to touch on some of the scenarios and ways to get your hands dirty, use the console and cement these concepts in your working knowledge. In turn this will make you a better AWS Solutions Architect, which is the whole point anyway! I recommend starting with good training courses to cover all the possible topics you may face. For the ones which you find more challenging, have less experience in, those are the ones you want to dive into more hands-on exercises, troubleshooting documentation, AWS whitepapers and all the training you can layer onto it. Something I’ve learned when tackling difficult concepts – it’s best to use as many layers as possible, hands-on, audio, lectures, re:Invent videos, layer your learning like an onion for maximum success.
![]()
Build a Centralized Logging Solution
Let’s look at Data Analytics in the lens of being a Solution Architect Professional. Many AWS Solution Architect Professional scenarios touch upon the optimal management of large multi-account environments. One such scenario is knowing how to deploy a centralized log solution. The following lab which will teach you key fundamental concepts which will increase your expertise and take you one step closer to being an AWS Certified Solution Architect Professional: AWS Solutions Library: Centralized Logging. This contains multiple CloudFormation templates for use in a primary and spoke accounts. It will deploy a solution that will collect and analyze heterogenous logs from AWS services, web servers, and applications in one easy to read dashboard. This solves the problem of organizing collecting and displaying your logs.
It will perform three actions : ingest, index and visualize. My favorite part of this one is that it gets you working with Amazon Kinesis Data Streams and Amazon Kinesis Data Firehose.
Exam Update
Do note that the AWS Certified Solutions Architect – Professional certification exam is changing November 15, 2022. With this you can be sure to expect newer services such as those in the AIML Suite. If you are in the preparation phase, I recommend completing and taking the exam before 11/15/22.
Amazon Kinesis Data Streams vs. Amazon Kinesis Data Firehose
Data Firehose is a fully managed Ingest, Transform and Load (ITL) solution. Since it’s fully managed you do not need any configuration. Note that it does not store data. For that you will need to work with Amazon Kinesis Data Streams. Firehose is more suited to stream data to S3, Redshift and Amazon Elasticsearch. If your problem requires a custom, real-time analytics solution then I recommend looking at Kinesis Data Streams, if instead you are looking for a continuous data load for analysis, and you don’t require data storage in the stream itself – then use Firehose. Kinesis data storage. Be sure to take time to understand data retention and scenarios like fan-out.
Questions to ask yourself
- What are common use cases for each service?
- What are the data retention periods, if any?
- Are there any anti-patterns?
A good starting point for these questions are the FAQS: Kinesis Data Streams FAQ and Kinesis Data Firehose FAQ . I also highly recommend reviewing the troubleshooting sections for the services you are studying deeply: Troubleshooting Amazon Kinesis Data Firehose.
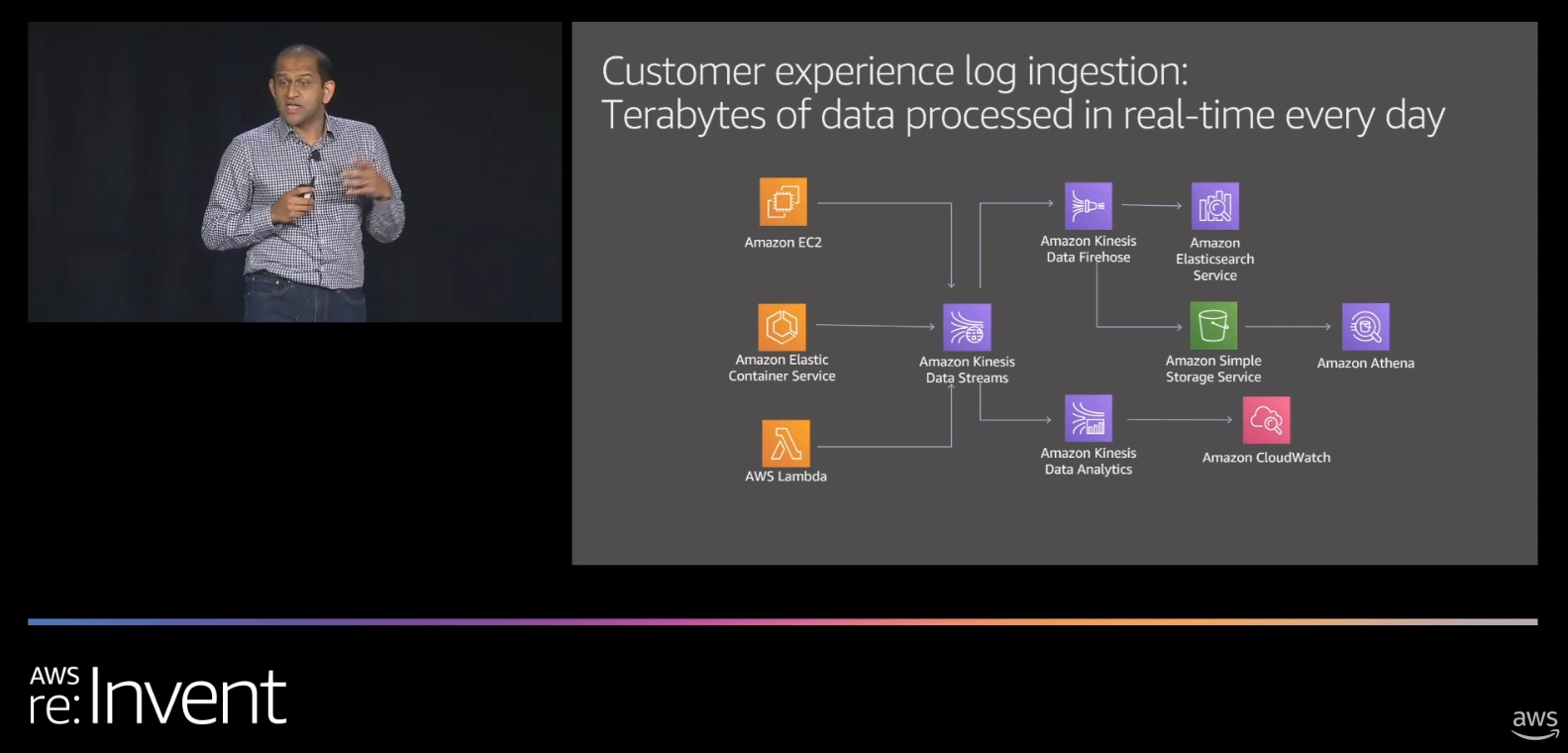
Remember – Kinesis Data Analytics is real-time! Source: AWS re:Invent 2019: Building a streaming data platform with Amazon Kinesis (ANT326-R1)
Kinesis Streams and Firehose Example
Kinesis Data Streams is more suited to custom applications but will also require more upfront planning , similar to on-demand vs. provisioned. Firehose, on the other hand, is a simpler solution to capture streaming data . Kinesis Firehose supports streaming data destinations of supports Amazon S3, Amazon Redshift, Amazon OpenSearch Service, Splunk, Datadog, NewRelic, Dynatrace, Sumologic, LogicMonitor, MongoDB, and HTTP End Point as destinations. As a source it supports writers to the Firehose API (such as IoT sensors, apps, log servers) , it also supports Kinesis Data Streams, reading from the stream and writing to a Firehose destination. It can also send to Lambda, EventBridge and other native AWS services are supported. A full list is available in the Developer Guide.
One practical example of Kinesis and Firehose working together is available in the AWS Architecture blog: Automating Anomaly Detection in Ecommerce Traffic Patterns – in summary – search data from a mobile application is ingested by Kinesis Data Streams, then Firehose reads from the stream, and sends to Lambda for data transformation.
Valuable Kinesis Data Streams Features to Note
- Kinesis Streams can support multiple subscribers – e.g. fan out.
- Kinesis Streams can replay data
Kinesis Data Analytics
- Analytics comes in two flavors now: SQL and Apache Flink
- This blog contains a CloudFormation template for hands-on work with these services: Get started with Flink SQL APIs in Amazon Kinesis Data Analytics Studio
- Using Analytics versus using a Lambda function in Firehose
- Analytics has benefit of doing in-stream analysis (and effectively creating multiple output streams of processed data) – examples of analysis being flattening (or simple ETL) of data or summarization (Common example being an in-game leaderboard)
On-Demand vs Provisioned
Released in November of 2021, a new capacity mode for Amazon Kinesis Data Streams was released: on-demand. The original, singular option was known as provisioned. Existing streams can be converted to on-demand with no downtime or code changes. With on-demand mode you are paying for throughput, not for provisioned resources. One of the benefits of on-demand is that it removes the burden of capacity planning – workloads are accommodated automatically as they scale up or down. On-demand is also a good choice for unpredictable workloads with large spikes.
With provisioned stream capacity, you have to specify the number of shards for the data stream. The data stream capacity is the sum of all shards with their respective capacity.
For on-demand you do need to specify partition keys for each record. If you use highly uneven partition keys it can lead to a write exception. If this is your case it would be wiser to use Provisioned stream capacity and split your shards accordingly. For provisioned mode you do need to perform upfront capacity planning and specify shards for the data stream.
Storage formats and trade offs
CSV is comprised of fixed column positions whereas JSON and optimized formats offer more flexibility in how the data can be stored/retrieved with the latter being more performant (Redshift Spectrum, Athena, etc.) and potentially less costly as a result.
Related Services – KMS and EventBridge
In December of 2020, server-side encryption was added to Kinesis Data Streams. This uses an Amazon Key Management Service (KMS) managed customer master key. For a deeper dive on this, please see the Developer Guide: Data Protection in Amazon Kinesis Data Streams. AWS API Call events can be sent to a Kinesis Data Stream using EventBridge. There is an AWS tutorial available in the EventBridge User Guide.
Layer your Learning
To layer our learning for Kinesis, take a look at the AWS Stash – it’s a great way to find specialized content. It indexes published AWS Videos, Quickstarts, Blogs, and more. For example, in this search – I’m looking for anything that matches ‘Kinesis’, video, level 300 and published in 2019: AWS Stash Kinesis Search The re:Invent videos are good and have helped me to dig deeper into tricky topics. More content included in the stash are: AWS prescriptive guidance, tech talks, and ‘This is my architecture’ series.
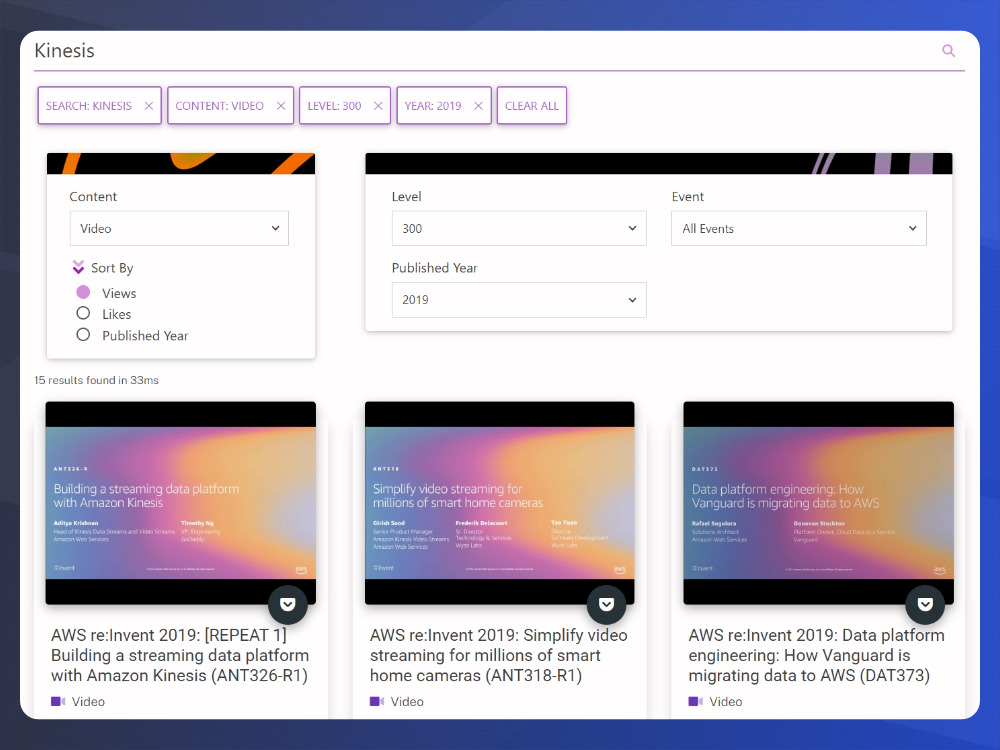
AWS Stash – Searching for Kinesis Videos – for this exam I recommend 300-400 level videos. Anything below may not be technical enough
Conclusion
With all these tools at your disposal, you are now much better equipped with what you need to master this challenging area of the exam. Set a time and routine for your practice, make it like a daily exercise, and ramp up as your exam gets closer. Good Luck!
Links and Further Reading
- Certified Solutions Architect Professional
- AWS Solutions Library: Centralized Logging
- AWS Training and Certification
- Solution Architect Professional – SAP-C01 Sample Questions
- AWS Stash
- Kinesis Data Streams FAQ
- Kinesis Data Firehose FAQ
- Troubleshooting Amazon Kinesis Data Firehose
- AWS Streaming Data Solution for Amazon MSK
- AWS Solutions Library
- AWS re:Invent 2019: Building a streaming data platform with Amazon Kinesis (ANT326-R1)
- Enhanced Fan-Out for Kinesis
- Automating Anomaly Detection in Ecommerce Traffic Patterns
- Kinesis Firehose Developer Guide
- Get started with Flink SQL APIs in Amazon Kinesis Data Analytics Studio
- Data Protection in Amazon Kinesis Data Streams
- EventBridge Kinesis Tutorial

Jorge Rodriguez
Lead Cloud Engineer
[email protected]


